อาลีบาบา คลาวด์ เปิดตัว “Qwen2.5-Omni-7B” โมเดลมัลติโหมด รองรับการประมวลผลผ่านอินพุตหลายประเภท ผสานการพัฒนา AI Agent ได้อย่างคล่องตัว ง่ายกับการต่อยอดแอปสั่งการด้วยเสียงอัจฉริยะ
รายงานข่าวจากอาลีบาบา คลาวด์ ประเทศไทย เปิดเผยว่า อาลีบาบา คลาวด์ เปิดตัว “Qwen2.5-Omni-7B” โมเดลมัลติโหมด (Multimodal Model) ที่ออกแบบโดยเน้นความสามารถในการเข้าใจประเภทของข้อมูลได้หลายรูปแบบและครอบคลุม
สามารถประมวลผลอินพุตหลากหลาย รวมถึงข้อความ รูปภาพ เสียง และ วิดีโอ สามารถสร้างการตอบสนองด้วยข้อความและคำพูดที่เป็นธรรมชาติได้แบบเรียลไทม์ นับเป็นการตั้งมาตรฐานใหม่ให้กับ Multimodal AI ที่สามารถปรับใช้กับอุปกรณ์ปลายทาง (Edge Devices) เช่น โทรศัพท์มือถือ และแล็ปท็อป
ปัจจุบันเปิดเป็นโมเดลโอเพ่นซอร์สบน Hugging Face และ GitHub สามารถเข้าใช้ผ่าน Qwen Chat และ ModelScope ซึ่งเป็นชุมชนโอเพ่นซอร์สของอาลีบาบา คลาวด์ โดยหลายปีที่ผ่านมา อาลีบาบา คลาวด์ ได้เปิดให้โมเดล Generative AI มากกว่า 200 โมเดลเป็นโอเพ่นซอร์ส
Qwen2.5-Omni-7B มอบประสิทธิภาพได้ทัดเทียมกับโมเดลเฉพาะแบบโหมดเดียวต่าง ๆ (Single-Modality Models) ที่มีขนาดใกล้เคียงกัน ถือเป็นการตั้งมาตรฐานใหม่ด้านการปฏิสัมพันธ์ด้วยเสียงแบบเรียลไทม์ การสร้างเสียงพูดที่เป็นธรรมชาติและชัดเจน และการทำตามคำสั่งเสียงอย่างครบวงจรจากต้นจนจบ
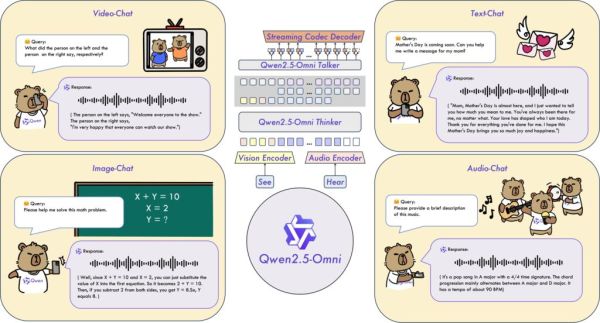
ประสิทธิภาพและสมรรถนะของโมเดลนี้มาจากการใช้สถาปัตยกรรมล้ำสมัย รวมถึง Thinker-Talker Architecture ที่แยกการสร้างข้อความ (ด้วย Thinker) และการสังเคราะห์เสียง (ด้วย Talker) ออกจากกัน เพื่อลดสัญญาณรบกวนจากโหมดต่าง ๆ ให้เหลือน้อยที่สุดเพื่อให้ได้เอาต์พุตคุณภาพสูง
รวมถึงใช้เทคนิค TMRoPE (Time-aligned Multimodal RoPE) ช่วยฝังตำแหน่งเพื่อให้ซิงโครไนซ์อินพุตวิดีโอด้วยเสียง พร้อมสร้างเนื้อหาที่สอดคล้องกันได้ดีขึ้น และ Block-wise Streaming Processing ที่ช่วยให้สามารถตอบสนองเสียงด้วยความรวดเร็วมีความหน่วงต่ำ ส่งผลให้การโต้ตอบด้วยเสียงเป็นไปอย่างราบรื่น
Qwen2.5-Omni-7B ได้รับการเทรนล่วงหน้าด้วยชุดข้อมูลที่หลากหลายและกว้างขวาง ซึ่งรวมถึงการเปลี่ยนภาพเป็นข้อความ, วิดีโอเป็นข้อความ, วิดีโอเป็นเสียง, ตัวอักษรเป็นข้อมูล เพื่อให้มั่นใจได้ว่าโมเดลจะสามารถทำงานได้ทุกแบบด้วยประสิทธิภาพสูง
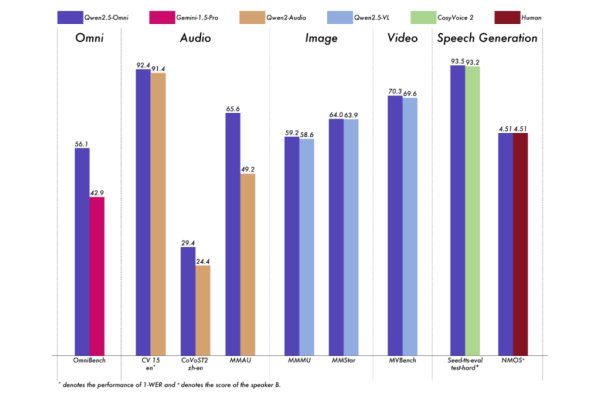
จุดเด่นของโมเดลนี้ คือการทำตามคำสั่งเสียง และมีประสิทธิภาพเทียบเท่ากับการป้อนเป็นตัวอักษรข้อความล้วน ๆ สำหรับงานที่เกี่ยวข้องกับมัลติโหมด เช่น โมเดลที่ได้รับการประเมินผ่าน OmniBench ซึ่งเป็นเกณฑ์มาตรฐานที่ประเมินความสามารถของโมเดลต่าง ๆ ด้านการจดจำ การตีความ และการให้เหตุผลจากอินพุตที่เป็นภาพ เสียงและข้อความ
Qwen2.5-Omni-7B ยังมีสมรรถนะในการทำความเข้าใจ และสร้างคำพูดผ่านการเรียนรู้ลงลึกในเชิงบริบท (In-Context Learning : ICL) เมื่อเสริมประสิทธิภาพด้วยการเรียนรู้แบบเสริมกำลัง (Reinforcement Learning : RL) หรือการเรียนรู้จากปฏิสัมพันธ์แบบลองผิดลองถูกที่เกิดขึ้นระหว่างทางของการเรียนรู้แล้ว โมเดลจึงมีความเสถียรในการสร้างคำพูดอย่างมาก ลดความคลาดเคลื่อนในการให้ความสนใจ ลดข้อผิดพลาดในการออกเสียง และลดการสะดุดระหว่างการตอบสนองด้วยคำพูดได้
ประสิทธิภาพของโมเดลนี้สามารถผสมผสานเข้ากับการพัฒนา AI Agent ได้อย่างคล่องตัว เพื่อต่อยอดเป็นแอปพลิเคชั่นเสียงอัจฉริยะต่าง ๆ เช่น การช่วยนำทางผู้มีความบกพร่องทางการมองเห็น ผ่านคำอธิบายเสียงเกี่ยวกับสภาพแวดล้อมแบบเรียลไทม์ หรือให้คำแนะนำในการทำอาหารทีละขั้นตอนด้วยการวิเคราะห์ส่วนผสมจากวิดีโอ หรือขับเคลื่อนให้บริการลูกค้าอัจริยะสามารถใช้บทสนทนาที่เข้าใจความต้องการของลูกค้าได้อย่างแท้จริง
ทั้งนี้ อาลีบาบา คลาวด์ เปิดตัว Qwen2.5 เมื่อเดือนกันยายน 2567 และปล่อย Qwen2.5-Max สู่ตลาดในเดือนมกราคม 2568 โดยได้รับการจัดให้อยู่ในอันดับที่ 7 บน Chatbot Arena ซึ่งเทียบชั้นได้กับ LLM ชั้นนำทั้งหลายที่มีกรรมสิทธิ์ และยังแสดงให้เห็นถึงความสามารถที่โดดเด่นในด้านต่าง ๆ